Labeling data with metadata (text, images, audio, video) so ML models can learn from it.

Better AI starts with well-labeled data
Data annotation is the process of adding clear labels and metadata to raw data so machine learning models can learn patterns correctly—especially in supervised learning. With the right labeling strategy, you reduce noise, improve model accuracy, and speed up iteration from prototype to production.
Let's Discuss →Data Annotation Delivery Essentials
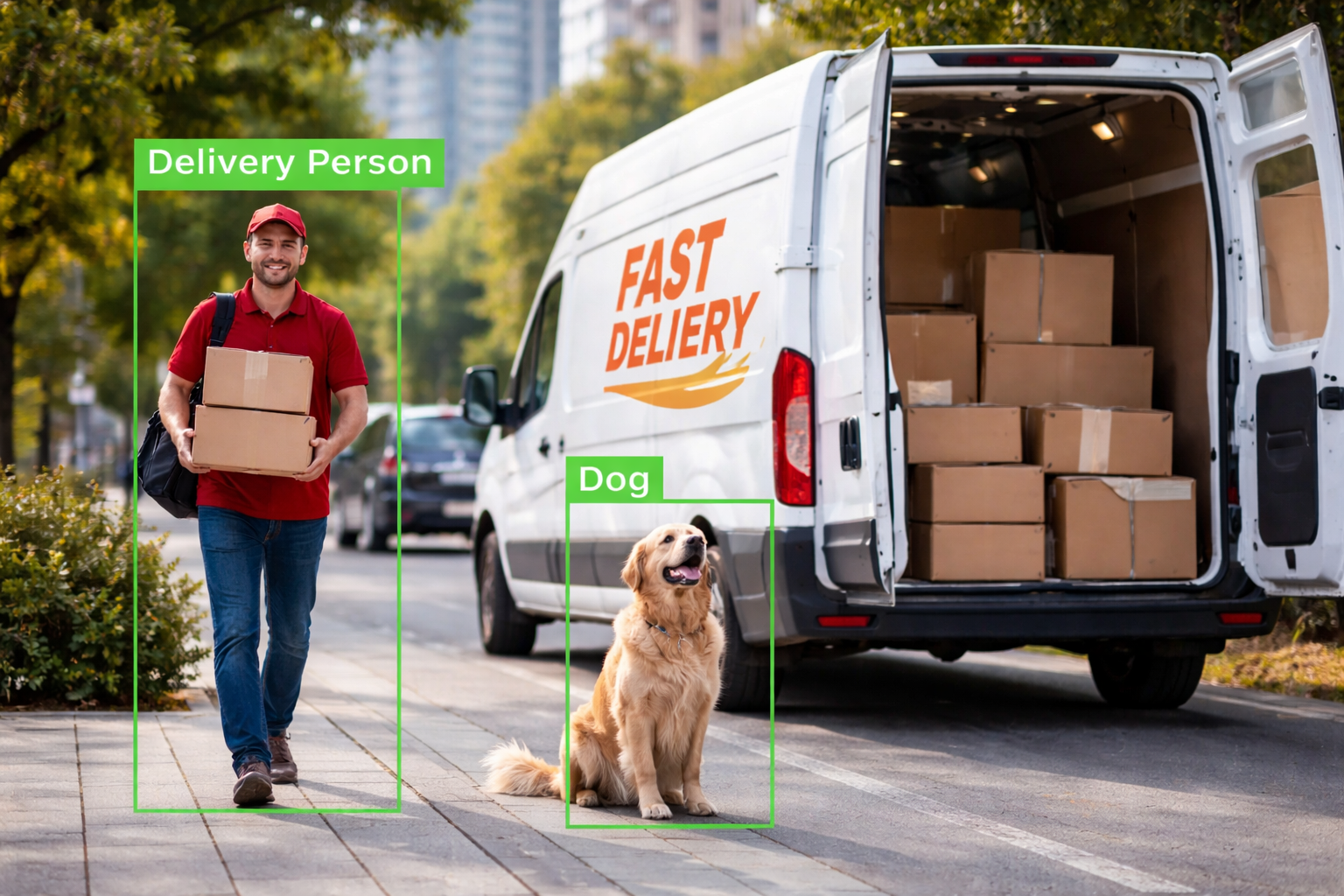
Image & Video Annotation
Bounding boxes, polygons, masks, keypoints, tracking—built for real-world computer vision use cases.
Quality Assurance
Multi-step QA with sampling, reviewer checks, and feedback loops to keep labels consistent across teams.
Scalable Teams
Start small with a pilot batch, then scale volume while keeping the same guidelines and audit trail.
What we annotate
We provide high-accuracy annotation services across multiple data types to support AI, machine learning, and autonomous systems.
Image Annotation
- Bounding boxes, Polygons
- Semantic/Instance Segmentation
- Keypoints / Pose
Video Annotation
- Tracking & Keyframes
- Activity / Action Labels
- Frame-level Masks where required
Text Annotation (NLP)
- Entity Tagging
- Intent / Sentiment Labels
- Classification Datasets
Audio Annotation
- Speech Transcription
- Speaker Labels
- Timestamps (when required)
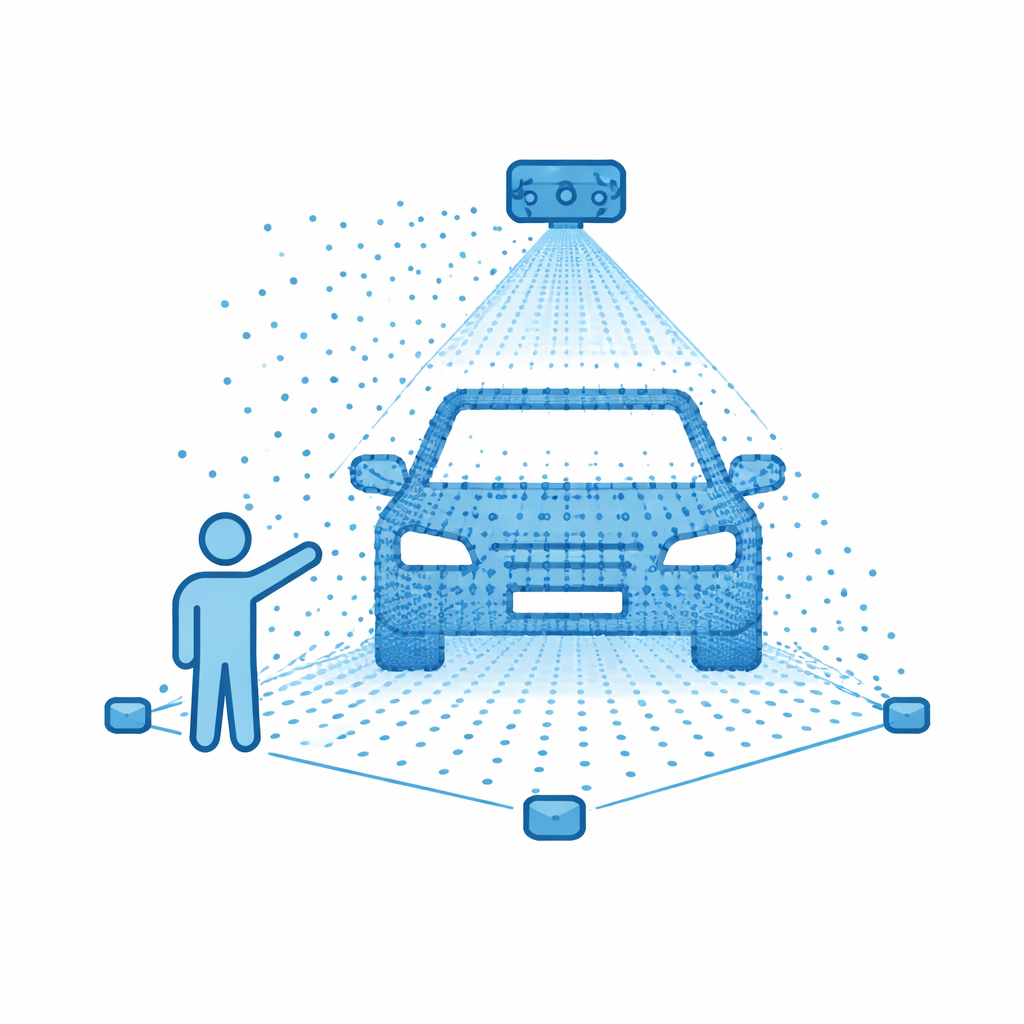
LiDAR / Point Cloud
- 3D Cuboids
- Lane / Road Elements
- Object Classes for Autonomy Workflows

Document / OCR Annotation
- Layout Detection Labels
- Table Structure Tagging
- Key Value Extraction
Why choose Skaro for data annotation?
- High annotation consistency
- Pilot-first approach (prove quality early)
- Bias-aware labeling guidelines
- Dedicated QA + reviewer workflow
- Secure handling (NDA + access control)
- Works across industries & use cases
Why data annotation matters
Without properly tagged data, AI systems can’t reach their full potential—good labels are the foundation for accurate model learning and evaluation.
Higher Model Accuracy
Consistent labels help models learn correct patterns, improving precision/recall and reducing false detections in production.
Faster Iteration Cycles
Clean, structured datasets reduce training rework—so your team can test, tune, and ship faster.
Better Real-World Performance
QA-backed labeling makes models more reliable across lighting, angles, occlusions, and real-world edge cases.
Our Process
Requirements & Label Taxonomy
Defining project needs
Labeling Guidelines & Examples
Instruction & samples
Pilot Batch (Quality Benchmark)
Initial quality assessment
Production Labeling
Full-scale annotation
QA Review & Corrections
Ensuring accuracy
Final Export & Delivery Report
Completed data delivery
Get a quick estimate & pilot plan
Share your dataset type, label classes, and target format. We’ll reply with a pilot timeline, QA approach, and pricing options.